# 腾讯音乐 C++ 面试

大家好,我是小林。
之前有读者留言想知道腾讯音乐的校招薪资 (opens new window)。

腾讯今年的校招薪资是有新变化 (opens new window)的,也就是将 16 薪资改为了 15 薪,最后一薪直接加到每月的月薪里了,每个月到手的钱相比以前多了,但是整体收入是没有变化的,比如原本 20k * 16,变成了 21.6 x 15。
腾讯音乐薪资一样也是变化了,16 薪变为了 15 薪。
可惜目前, 25 届腾讯音乐开发岗的薪资数据不多,目前只发现了下面这一个:
- 25.5k x 15 + 2k x 12(房补) + 6w(股票分 2 年发) + 3w(签字费)= 46w 总包
这里也贴一下往届腾讯音乐开发岗的校招薪资情况,那时候是 16 薪,可以作为一个参考:
- 24k x 16 + 3k x 12(房补)+5w(股票分 2 年发)+ 5w(签字费)= 49.5w 总包
- 23k x 16 + 3k x 12(房补)+ 3w (股票分 2 年发) + 3w(签字费)= 44.9w 总包
- 20.5k x 16 + 3k x 12(房补) + 3w(签字费)= 39.4w
- 19.5k x 16 + 3k x 12(房补) + 2w(签字费) = 36.8w
腾讯音乐的面试跟腾讯没有什么太大的区别,都是大厂面试难度,之前也有训练营 (opens new window)同学拿到了腾讯音乐的 offer,面完泡了很久,才开出来了,这种大概率是前面有人鸽了,等等党的胜利了。
不过,也看到有同学面腾讯音乐的时候,感觉题目不是很难,就是基础问题,而且也感觉面试官在对着题库念,回答完之后也没有反应,说完一个问题就直接开始下一个问题,这场面试有点机械感,不出所料,最后还是挂了,让同学觉得是 kpi 面。
然后,也有同学看了这个面经,说跟他当时面的时候一模一样,算法题都一样,结果也是挂了。
那这次我们就来看看同学所说的腾讯音乐的 “KPI” 后端开发的一面,同学的技术栈是 C++,所以主要是问了C++、Linux、操作系统、数据库、算法这些知识。
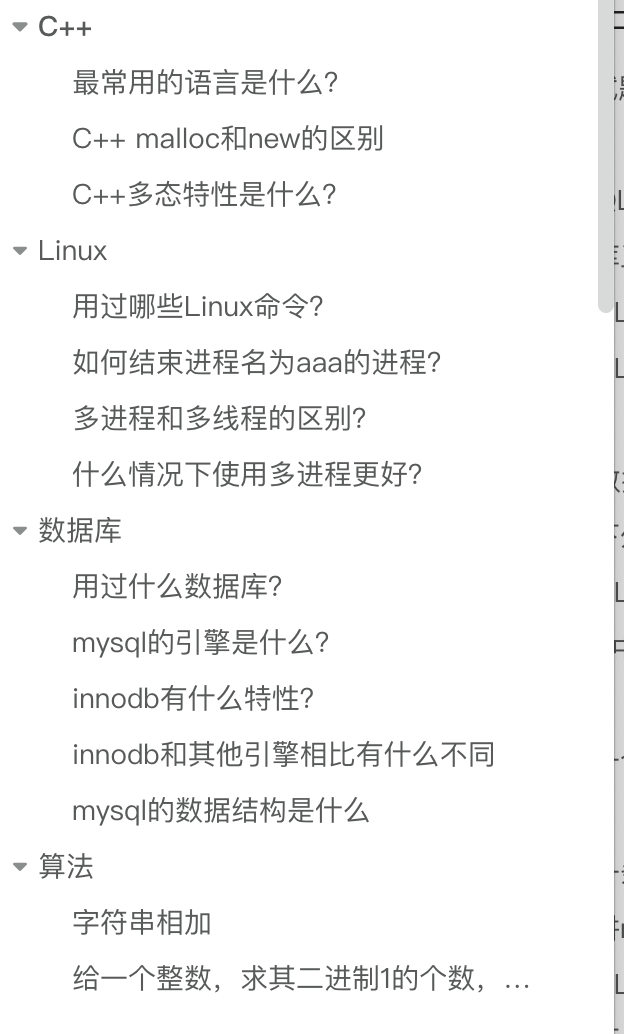
# C++
# 最常用的语言是什么?
我常用的是c++
# C++ malloc和new的区别
- 语法不同:malloc/free是一个C语言的函数,而new/delete是C++的运算符。
- 分配内存的方式不同:malloc只分配内存,而new会分配内存并且调用对象的构造函数来初始化对象。
- 返回值不同:malloc返回一个 void 指针,需要自己强制类型转换,而new返回一个指向对象类型的指针。
- malloc 需要传入需要分配的大小,而 new 编译器会自动计算所构造对象的大小
# C++多态特性是什么?
多态是面向对象编程(OOP)的重要特性之一,它允许不同的对象对同一消息(函数调用)做出不同的响应。在 C++ 中,多态主要通过虚函数来实现。
多态有静态多态和动态多态两种:
- **静态多态(编译时多态):**主要通过函数重载来实现。函数重载是指在同一个作用域内,可以有多个同名函数,但是它们的参数列表(参数个数、参数类型或者参数顺序)不同。例如:
int add(int a, int b) {
return a + b;
}
double add(double a, double b) {
return a + b;
}
当调用add函数时,编译器会根据传入的参数类型和个数在编译时期就确定调用哪个版本的add函数。
- **动态多态(运行时多态):**基于虚函数和继承来实现。它允许在运行时根据对象的实际类型来调用相应的函数。当一个类包含虚函数时,编译器会为这个类创建一个虚函数表。虚函数表是一个函数指针数组,其中存储了这个类的虚函数的地址。每个包含虚函数的类的对象中都会包含一个虚函数指针,这个指针指向该类的虚函数表。当通过基类指针或引用调用虚函数时,程序会根据虚函数指针找到对应的虚函数表,然后在虚函数表中查找要调用的虚函数的实际地址,从而实现根据对象的实际类型来调用函数。
# Linux
# 用过哪些Linux命令?
- **文件和目录操作命令:**ls、cd、mkdir、pwd、cp、mv、rm
- **文件内容查看和编辑命令:cat、**tail、less、more、head、vi
- **系统信息查看命令:**ps、top、free、df、du
- **用户和权限管理命令:**chmod
- **网络相关命令:**tcpudmp、ifconfig、ping、netstat、wget
# 如何结束进程名为aaa的进程?
- 首先,需要找到进程名为 “aaa” 的进程 ID(PID)。可以使用
pgrep命令来查找,pgrep命令用于查找当前运行进程的 PID,它会根据进程名称进行匹配。命令格式为pgrep [选项] 进程名。例如,pgrep aaa会返回名为 “aaa” 的所有进程的 PID。 - 然后,使用
kill命令来结束进程。kill命令用于向指定的进程发送信号,默认发送的是SIGTERM信号,该信号会请求进程正常终止。一般情况下,进程收到这个信号后会进行一些清理工作然后终止。命令格式为kill [选项] PID。例如,如果通过pgrep aaa得到的 PID 是 1234,那么可以使用kill 1234来结束这个进程。 - 如果进程对
SIGTERM信号无响应,还可以使用kill -9 PID(其中-9表示发送SIGKILL信号)来强制结束进程。不过这种方式可能会导致进程没有机会进行清理操作,有可能丢失数据,应该谨慎使用。例如,kill -9 $(pgrep aaa)会强制结束所有名为 “aaa” 的进程。
# 多进程和多线程的区别?
资源分配方面的区别:
- 多进程:每个进程都有独立的地址空间,这意味着它们在内存中有自己独立的区域来存储代码、数据和堆栈等。例如,一个进程的全局变量在另一个进程中是不可见的,进程之间的数据交换相对复杂,需要通过进程间通信(IPC)机制,如管道、消息队列、共享内存等来实现。
- 多线程:线程共享进程的地址空间,因此线程之间共享全局变量和堆内存等资源。这使得线程之间的数据共享相对简单,比如在一个多线程的服务器程序中,多个线程可以直接访问和修改共享的数据结构,如连接队列等。线程的创建和销毁相对进程来说开销较小,因为它们共享了进程的大部分资源,不需要重新分配像进程那样完整的资源集合。不过,由于线程共享资源,可能会导致资源竞争问题,需要通过同步机制(如互斥锁、信号量等)来解决。
调度和执行方面的区别:
- **多进程:**进程间的切换开销相对较大,因为涉及到整个地址空间的切换、保存和恢复进程的上下文(包括寄存器的值、程序计数器等)。例如,从一个运行的文本编辑器进程切换到浏览器进程时,需要保存文本编辑器进程的完整状态,然后加载浏览器进程的状态。。
- 多线程:线程之间的切换相对进程来说开销较小,因为它们共享地址空间,只需要切换线程的私有数据(如栈指针、程序计数器等)和保存恢复一些寄存器的值。
稳定性和可靠性方面:
- 多进程:一个进程的崩溃(例如出现段错误等)通常不会影响其他进程的正常运行,因为每个进程都有独立的地址空间和资源。这使得系统的稳定性相对较高,例如,在一个服务器系统中,即使一个服务进程(如邮件服务进程)崩溃,其他服务进程(如 Web 服务进程)仍然可以继续工作。
- 多线程:由于线程共享进程的资源,一个线程出现问题(如访问非法地址、死锁等)可能会导致整个进程崩溃。例如,在一个多线程的数据库服务器程序中,如果一个线程因为错误的内存访问而崩溃,可能会导致整个服务器进程退出,影响系统的可靠性。
# 什么情况下使用多进程更好?
- 安全性和稳定性:当程序的不同部分对稳定性和安全性要求很高,并且彼此之间的错误可能会相互影响时,多进程是很好的选择。例如,在一个服务器系统中,有 Web 服务进程和数据库服务进程。如果 Web 服务进程因为遭受恶意攻击或者出现代码错误而崩溃,由于数据库服务进程是独立的,其数据和运行不会受到直接影响,从而保证了数据的安全性和系统的部分功能依然可用。
- 不同语言的兼容性:如果需要在一个应用程序中集成多种编程语言编写的模块,多进程可以提供简单的解决方案。例如,有一个系统,一部分是用 Python 编写的数据分析模块,另一部分是用 C++ 编写的高性能计算模块。由于不同语言的运行时环境、内存管理等可能存在差异,使用多进程可以让每个模块在自己独立的进程中运行,避免语言之间的相互干扰。
# 数据库
# 用过什么数据库?
主要用过 mysql
# mysql的引擎是什么?
- InnoDB:InnoDB是MySQL的默认存储引擎,具有ACID事务支持、行级锁、外键约束等特性。它适用于高并发的读写操作,支持较好的数据完整性和并发控制。
- MyISAM:MyISAM是MySQL的另一种常见的存储引擎,具有较低的存储空间和内存消耗,适用于大量读操作的场景。然而,MyISAM不支持事务、行级锁和外键约束,因此在并发写入和数据完整性方面有一定的限制。
- Memory:Memory引擎将数据存储在内存中,适用于对性能要求较高的读操作,但是在服务器重启或崩溃时数据会丢失。它不支持事务、行级锁和外键约束。
# innodb有什么特性?
InnoDB引擎在事务支持、并发性能、崩溃恢复等方面具有优势,因此被MySQL选择为默认的存储引擎。
- 事务支持:InnoDB引擎提供了对事务的支持,可以进行ACID(原子性、一致性、隔离性、持久性)属性的操作。Myisam存储引擎是不支持事务的。
- 并发性能:InnoDB引擎采用了行级锁定的机制,可以提供更好的并发性能,Myisam存储引擎只支持表锁,锁的粒度比较大。
- 崩溃恢复:InnoDB引引擎通过 redolog 日志实现了崩溃恢复,可以在数据库发生异常情况(如断电)时,通过日志文件进行恢复,保证数据的持久性和一致性。Myisam是不支持崩溃恢复的。
# innodb和其他引擎相比有什么不同
mysql的innodb与MyISAM的区别如下:
- 事务:InnoDB 支持事务,MyISAM 不支持事务,这是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一。
- 索引结构:InnoDB 是聚簇索引,MyISAM 是非聚簇索引。聚簇索引的文件存放在主键索引的叶子节点上,因此 InnoDB 必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而 MyISAM 是非聚簇索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
- 锁粒度:InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限。
- count 的效率:InnoDB 不保存表的具体行数,执行 select count(*) from table 时需要全表扫描。而MyISAM 用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快。
# mysql的数据结构是什么
MySQL InnoDB 引擎是用了B+树作为了索引的数据结构。
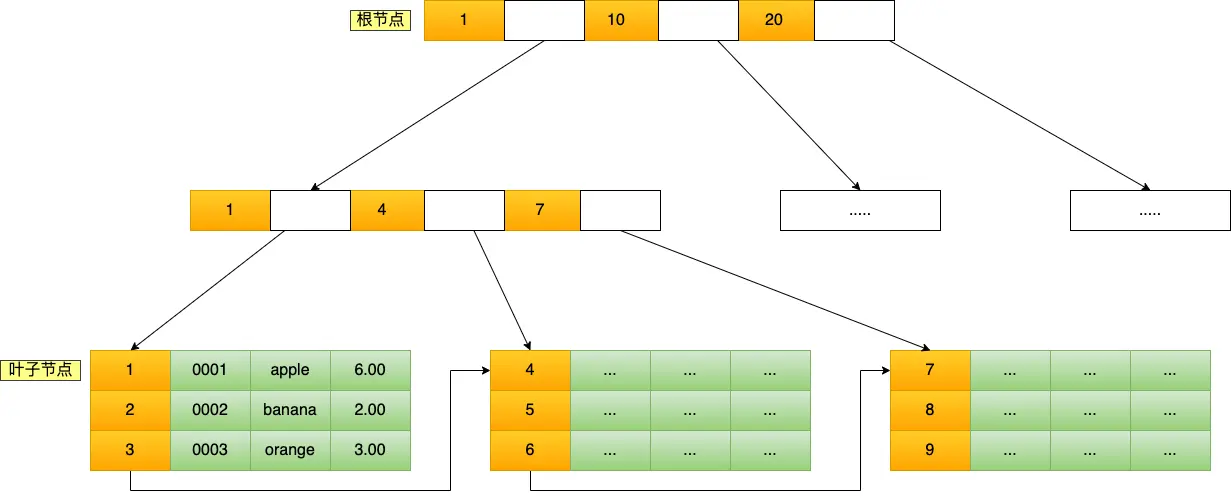
B+Tree 是一种多叉树,叶子节点才存放数据,非叶子节点只存放索引,而且每个节点里的数据是按主键顺序存放的。每一层父节点的索引值都会出现在下层子节点的索引值中,因此在叶子节点中,包括了所有的索引值信息,并且每一个叶子节点都有两个指针,分别指向下一个叶子节点和上一个叶子节点,形成一个双向链表。
主键索引的 B+Tree 如图所示:
比如,我们执行了下面这条查询语句:
select * from product where id= 5;
这条语句使用了主键索引查询 id 号为 5 的商品。查询过程是这样的,B+Tree 会自顶向下逐层进行查找:
- 将 5 与根节点的索引数据 (1,10,20) 比较,5 在 1 和 10 之间,所以根据 B+Tree的搜索逻辑,找到第二层的索引数据 (1,4,7);
- 在第二层的索引数据 (1,4,7)中进行查找,因为 5 在 4 和 7 之间,所以找到第三层的索引数据(4,5,6);
- 在叶子节点的索引数据(4,5,6)中进行查找,然后我们找到了索引值为 5 的行数据。
数据库的索引和数据都是存储在硬盘的,我们可以把读取一个节点当作一次磁盘 I/O 操作。那么上面的整个查询过程一共经历了 3 个节点,也就是进行了 3 次 I/O 操作。
B+Tree 存储千万级的数据只需要 3-4 层高度就可以满足,这意味着从千万级的表查询目标数据最多需要 3-4 次磁盘 I/O,所以B+Tree 相比于 B 树和二叉树来说,最大的优势在于查询效率很高,因为即使在数据量很大的情况,查询一个数据的磁盘 I/O 依然维持在 3-4次。
# 算法
# 字符串相加
解题思路:将两个字符串表示的数字看作是按位排列的数字,从低位(字符串末尾)开始逐位相加,同时考虑进位情况,就如同我们在纸上进行竖式加法运算一样。
代码实现:
#include <iostream>
#include <string>
using namespace std;
string addStrings(string num1, string num2) {
string result;
int i = num1.size() - 1, j = num2.size() - 1;
int carry = 0; // 进位
while (i >= 0 || j >= 0 || carry > 0) {
int n1 = i >= 0? num1[i--] - '0' : 0;
int n2 = j >= 0? num2[j--] - '0' : 0;
int sum = n1 + n2 + carry;
carry = sum / 10;
result.push_back(sum % 10 + '0');
}
return string(result.rbegin(), result.rend());
}
int main() {
string num1 = "123";
string num2 = "456";
string sum = addStrings(num1, num2);
cout << sum << endl;
return 0;
}
# 给一个整数,求其二进制1的个数,负数取补码
解题思路:通过循环对整数的每一位进行判断,利用位运算中的与运算(&)来检查当前位是否为 1。具体来说,将整数与 1 进行与运算,如果结果为 1,则表示当前最低位是 1,然后将整数右移一位,继续检查下一位,直到整数变为 0 为止。
代码实现:
#include <iostream>
using namespace std;
int countOnes(int num) {
int count = 0;
while (num!= 0) {
if (num & 1) {
count++;
}
num >>= 1;
}
return count;
}
int main() {
int num = -5;
int result = countOnes(num);
cout << "二进制表示中1的个数为: " << result << endl;
return 0;
}
对了,最新的互联网大厂后端面经都会在公众号首发,别忘记关注哦!!如果你想加入百人技术交流群,扫码下方二维码回复「加群」。
