# 阿里云 Java 面试

大家好,我是小林。
很多人都有一个疑问,不知道如何在拿到 offer 之后跟 hr 谈薪资。
其实谈薪资最重要的是积攒筹码,那什么是筹码呢?就是你手上的 offer。
如果你拿到了好几个 offer,那已经说明你在市场上被多家公司认可了,这时候谈薪的时候,你会更优势的,而且成功率也会更大一些。
比如你手上拿了 1 个 20k offer,跟下一家谈的时候,就可以喊 23k 的期望薪资,当然还是需要表达一下,你更想加入这家公司。
那么,我们来看看 25 届阿里云开发岗的校招薪资情况如下:

- 32k * 16 + 8w 签字费,同学背景硕士 985,城市北京
- 30k * 16 + 5w 签字费,同学背景硕士 985,城市杭州
- 28k * 16 + 5w 签字费,同学背景硕士 985,城市北京
- 27k * 16,同学背景硕士海龟,城市杭州
- 25k * 16,同学背景硕士985,城市北京
整体年包在 40w-60w,还是非常具有竞争力的,除了薪资之外,还会还有交通补贴和餐补,而且杭州还会有政府的人才补贴。
这次跟大家分享一下阿里云Java 后端的校招面经,这个是电话一面,主要是以拷打技术基础为主,主要是考察了MySQL+Java+Redis+Linux 的知识,由于是电话面,最后是口述算法逻辑。
阿里云面经具体的面试问题如下,大家觉得难得如何呢?

# MySQL
# 事务隔离级别有哪些?
- 读未提交(read uncommitted),指一个事务还没提交时,它做的变更就能被其他事务看到;
- 读提交(read committed),指一个事务提交之后,它做的变更才能被其他事务看到;
- 可重复读(repeatable read),指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQL InnoDB 引擎的默认隔离级别;
- 串行化(serializable);会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行;
按隔离水平高低排序如下:

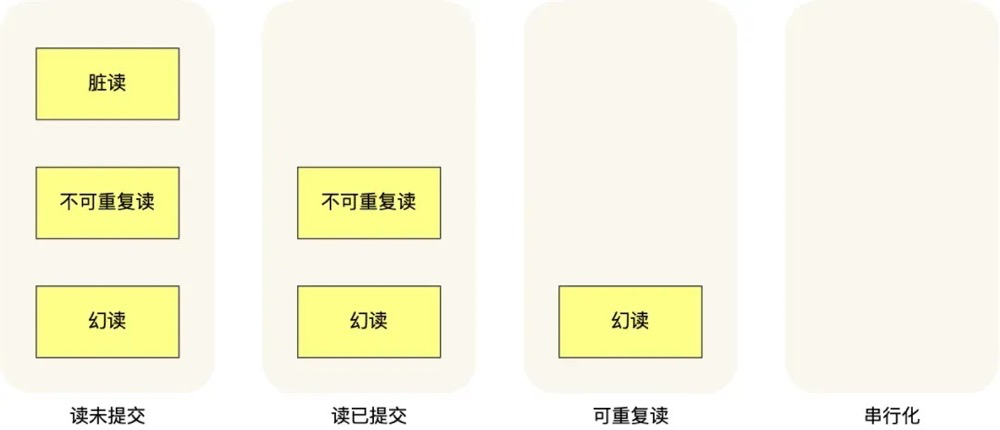
针对不同的隔离级别,并发事务时可能发生的现象也会不同。
 也就是说:
也就是说:
- 在「读未提交」隔离级别下,可能发生脏读、不可重复读和幻读现象;
- 在「读提交」隔离级别下,可能发生不可重复读和幻读现象,但是不可能发生脏读现象;
- 在「可重复读」隔离级别下,可能发生幻读现象,但是不可能脏读和不可重复读现象;
- 在「串行化」隔离级别下,脏读、不可重复读和幻读现象都不可能会发生。
# 幻读和脏读的区别?
脏读
如果一个事务「读到」了另一个「未提交事务修改过的数据」,就意味着发生了「脏读」现象。
举个栗子。
假设有 A 和 B 这两个事务同时在处理,事务 A 先开始从数据库中读取小林的余额数据,然后再执行更新操作,如果此时事务 A 还没有提交事务,而此时正好事务 B 也从数据库中读取小林的余额数据,那么事务 B 读取到的余额数据是刚才事务 A 更新后的数据,即使没有提交事务。
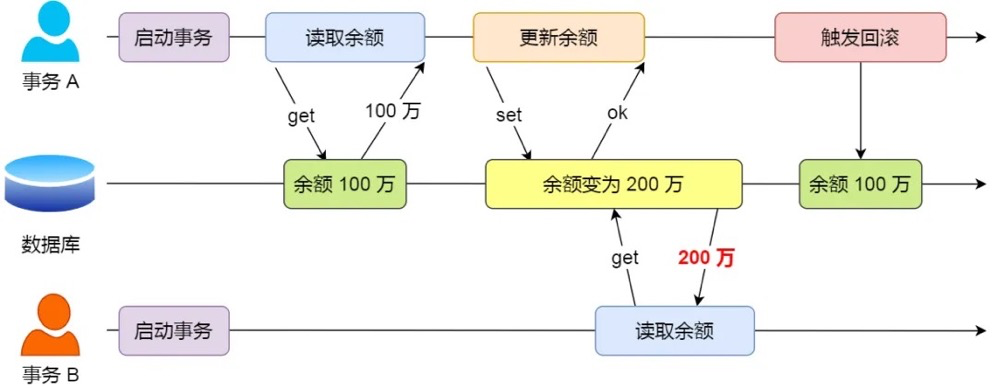
因为事务 A 是还没提交事务的,也就是它随时可能发生回滚操作,如果在上面这种情况事务 A 发生了回滚,那么事务 B 刚才得到的数据就是过期的数据,这种现象就被称为脏读。
幻读
在一个事务内多次查询某个符合查询条件的「记录数量」,如果出现前后两次查询到的记录数量不一样的情况,就意味着发生了「幻读」现象。
举个栗子。
假设有 A 和 B 这两个事务同时在处理,事务 A 先开始从数据库查询账户余额大于 100 万的记录,发现共有 5 条,然后事务 B 也按相同的搜索条件也是查询出了 5 条记录。
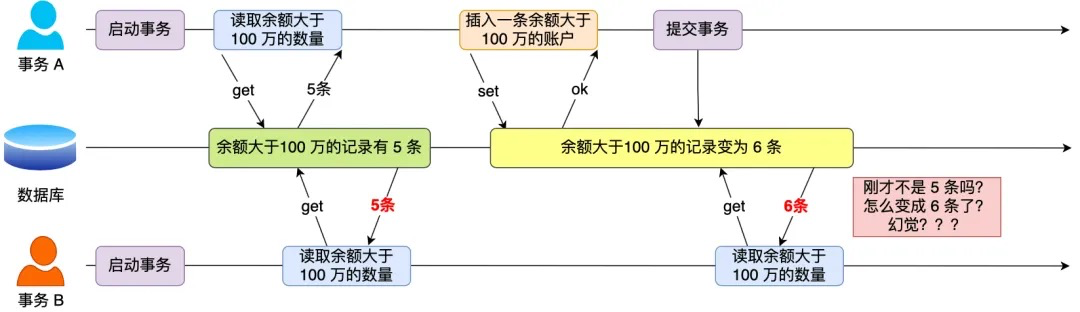
接下来,事务 A 插入了一条余额超过 100 万的账号,并提交了事务,此时数据库超过 100 万余额的账号个数就变为 6。
然后事务 B 再次查询账户余额大于 100 万的记录,此时查询到的记录数量有 6 条,发现和前一次读到的记录数量不一样了,就感觉发生了幻觉一样,这种现象就被称为幻读。
# 如何防止幻读?
MySQL InnoDB 引擎的默认隔离级别虽然是「可重复读」,但是它很大程度上避免幻读现象(并不是完全解决了),解决的方案有两种:
- 针对快照读(普通 select 语句),是通过 MVCC 方式解决了幻读,因为可重复读隔离级别下,事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,即使中途有其他事务插入了一条数据,是查询不出来这条数据的,所以就很好了避免幻读问题。
- 针对当前读(select ... for update 等语句),是通过 next-key lock(记录锁+间隙锁)方式解决了幻读,因为当执行 select ... for update 语句的时候,会加上 next-key lock,如果有其他事务在 next-key lock 锁范围内插入了一条记录,那么这个插入语句就会被阻塞,无法成功插入,所以就很好了避免幻读问题。
# 事务的mvcc机制原理是什么?
MVCC允许多个事务同时读取同一行数据,而不会彼此阻塞,每个事务看到的数据版本是该事务开始时的数据版本。这意味着,如果其他事务在此期间修改了数据,正在运行的事务仍然看到的是它开始时的数据状态,从而实现了非阻塞读操作。
对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 Read View 来实现的,它们的区别在于创建 Read View 的时机不同,大家可以把 Read View 理解成一个数据快照,就像相机拍照那样,定格某一时刻的风景。
- 「读提交」隔离级别是在「每个select语句执行前」都会重新生成一个 Read View;
- 「可重复读」隔离级别是执行第一条select时,生成一个 Read View,然后整个事务期间都在用这个 Read View。
Read View 有四个重要的字段:
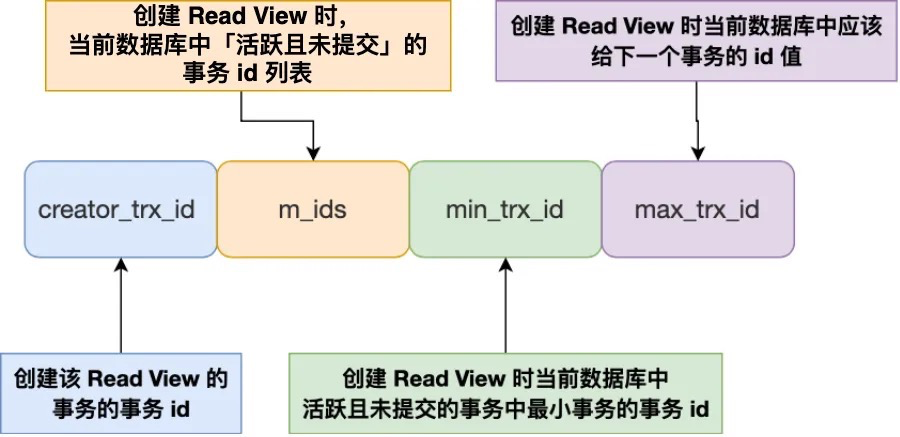
- m_ids :指的是在创建 Read View 时,当前数据库中「活跃事务」的事务 id 列表,注意是一个列表,“活跃事务”指的就是,启动了但还没提交的事务。
- min_trx_id :指的是在创建 Read View 时,当前数据库中「活跃事务」中事务 id 最小的事务,也就是 m_ids 的最小值。
- max_trx_id :这个并不是 m_ids 的最大值,而是创建 Read View 时当前数据库中应该给下一个事务的 id 值,也就是全局事务中最大的事务 id 值 + 1;
- creator_trx_id :指的是创建该 Read View 的事务的事务 id。
对于使用 InnoDB 存储引擎的数据库表,它的聚簇索引记录中都包含下面两个隐藏列:
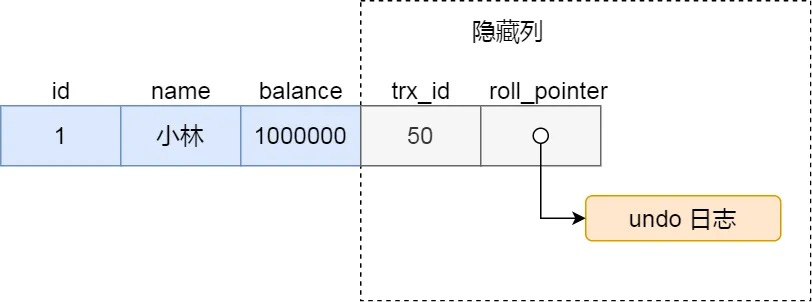
- trx_id,当一个事务对某条聚簇索引记录进行改动时,就会把该事务的事务 id 记录在 trx_id 隐藏列里;
- roll_pointer,每次对某条聚簇索引记录进行改动时,都会把旧版本的记录写入到 undo 日志中,然后这个隐藏列是个指针,指向每一个旧版本记录,于是就可以通过它找到修改前的记录。
在创建 Read View 后,我们可以将记录中的 trx_id 划分这三种情况:
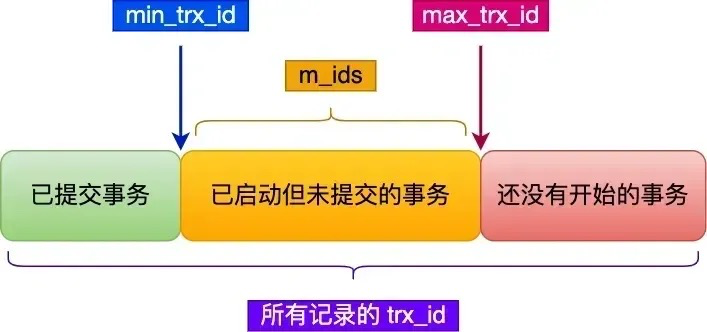
一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
- 如果记录的 trx_id 值小于 Read View 中的 min_trx_id 值,表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务可见。
- 如果记录的 trx_id 值大于等于 Read View 中的 max_trx_id 值,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务不可见。
- 如果记录的 trx_id 值在 Read View 的 min_trx_id 和 max_trx_id 之间,需要判断 trx_id 是否在 m_ids 列表中:
- 如果记录的 trx_id 在 m_ids 列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。
- 如果记录的 trx_id 不在 m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。
这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)。
# mysql的什么命令会加上间隙锁?
在可重复读隔离级别下。
- 当你使用非唯一索引进行查询时,InnoDB可能会在索引间隙上加上间隙锁,例如
SELECT * FROM t WHERE a = ? FOR UPDATE;如果a是非唯一索引,MySQL会在该值的前后加上间隙锁,以防止其他事务在这些间隙插入新记录。 - 在执行带有
WHERE条件的DELETE语句时,如果使用的是非唯一索引,MySQL会在符合条件的记录的前后加上间隙锁。 - 类似地,在执行带有
WHERE条件的UPDATE语句时,如果使用的是非唯一索引,MySQL也会在符合条件的记录的前后加上间隙锁。
# Java
# 双亲委派机制是什么?
双亲委派机制是Java类加载器(ClassLoader)中的一种工作原理。
它主要用于解决类加载过程中的安全和避免重复加载的问题。在这个机制中,类加载器之间存在层次关系,每个类加载器都有一个父加载器。当一个类需要被加载时,加载请求会从当前加载器开始,逐级向上委托给父加载器,直到根加载器(Bootstrap ClassLoader)。如果根加载器无法加载该类,那么委托链上的每个加载器都会尝试加载,直到找到合适的加载器或者无法加载为止。
双亲委派机制的好处:
- 保证类的唯一性:通过委托机制,确保了所有加载请求都会传递到启动类加载器,避免了不同类加载器重复加载相同类的情况,保证了Java核心类库的统一性,也防止了用户自定义类覆盖核心类库的可能。
- 保证安全性:由于Java核心库被启动类加载器加载,而启动类加载器只加载信任的类路径中的类,这样可以防止不可信的类假冒核心类,增强了系统的安全性。例如,恶意代码无法自定义一个java.lang.System类并加载到JVM中,因为这个请求会被委托给启动类加载器,而启动类加载器只会加载标准的Java库中的类。
- 支持隔离和层次划分:双亲委派模型支持不同层次的类加载器服务于不同的类加载需求,如应用程序类加载器加载用户代码,扩展类加载器加载扩展框架,启动类加载器加载核心库。这种层次化的划分有助于实现沙箱安全机制,保证了各个层级类加载器的职责清晰,也便于维护和扩展。
- 简化了加载流程:通过委派,大部分类能够被正确的类加载器加载,减少了每个加载器需要处理的类的数量,简化了类的加载过程,提高了加载效率。
# 垃圾回收 cms和g1的区别是什么?
区别一:使用的范围不一样:
- CMS收集器是老年代的收集器,可以配合新生代的Serial和ParNew收集器一起使用
- G1收集器收集范围是老年代和新生代。不需要结合其他收集器使用
区别二:STW的时间:
- CMS收集器以最小的停顿时间为目标的收集器。
- G1收集器可预测垃圾回收的停顿时间(建立可预测的停顿时间模型)
区别三: 垃圾碎片
- CMS收集器是使用“标记-清除”算法进行的垃圾回收,容易产生内存碎片
- G1收集器使用的是“标记-整理”算法,进行了空间整合,没有内存空间碎片。
区别四: 垃圾回收的过程不一样

注意这两个收集器第四阶段得不同
区别五: 两者都会产生浮动垃圾
- CMS 在并发清除阶段,用户线程和 GC 线程同时工作会产生浮动垃圾,这些垃圾只能等下一轮 GC 才能回收,因此 CMS 必须预留一部分内存空间用于存放浮动垃圾;若预留空间不足会触发
Concurrent Mode Failure,退化为 Serial Old 进行 Full GC。 - G1 同样会产生浮动垃圾:在并发标记阶段,用户线程继续运行产生的新垃圾在本轮周期内标记不到,只能等下一次回收。若 Mixed GC 在回收(Evacuation)过程中目标 Region 空间不足,会触发
Evacuation Failure(to-space exhausted),进而退化为 Full GC。
# spring三级缓存解决循环依赖问题?
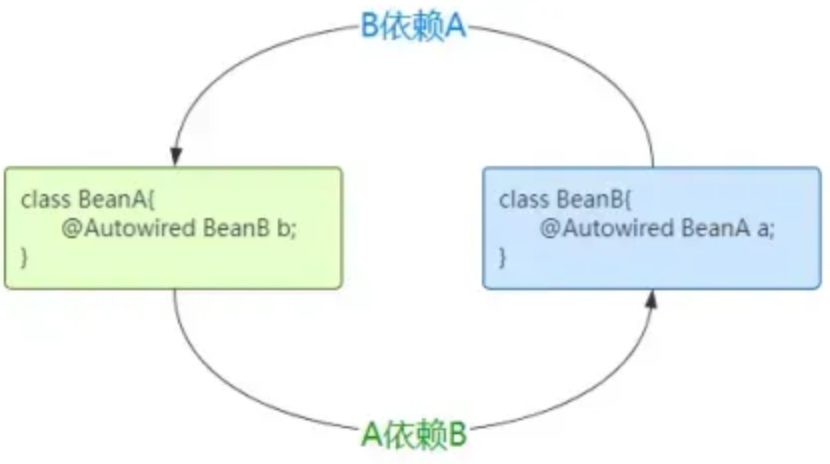
循环依赖指的是两个类中的属性相互依赖对方:例如 A 类中有 B 属性,B 类中有 A属性,从而形成了一个依赖闭环,如下图。
循环依赖问题在Spring中主要有三种情况:
- 第一种:通过构造方法进行依赖注入时产生的循环依赖问题。
- 第二种:通过setter方法进行依赖注入且是在多例(原型)模式下产生的循环依赖问题。
- 第三种:通过setter方法进行依赖注入且是在单例模式下产生的循环依赖问题。
只有【第三种方式】的循环依赖问题被 Spring 解决了,其他两种方式在遇到循环依赖问题时,Spring都会产生异常。
Spring 在 DefaultSingletonBeanRegistry 类中维护了三个重要的缓存 (Map),称为“三级缓存”:
singletonObjects(一级缓存):存放的是完全初始化好的、可用的 Bean 实例,getBean()方法最终返回的就是这里面的 Bean。此时 Bean 已实例化、属性已填充、初始化方法已执行、AOP 代理(如果需要)也已生成。earlySingletonObjects(二级缓存):存放的是提前暴露的 Bean 的原始对象引用 或 早期代理对象引用,专门用来处理循环依赖。当一个 Bean 还在创建过程中(尚未完成属性填充和初始化),但它的引用需要被注入到另一个 Bean 时,就暂时放在这里。此时 Bean 已实例化(调用了构造函数),但属性尚未填充,初始化方法尚未执行,它可能是一个原始对象,也可能是一个为了解决 AOP 代理问题而提前生成的代理对象。singletonFactories(三级缓存):存放的是 Bean 的ObjectFactory工厂对象。,这是解决循环依赖和 AOP 代理协同工作的关键。当 Bean 被实例化后(刚调完构造函数),Spring 会创建一个ObjectFactory并将其放入三级缓存。这个工厂的getObject()方法负责返回该 Bean 的早期引用(可能是原始对象,也可能是提前生成的代理对象),当检测到循环依赖需要注入一个尚未完全初始化的 Bean 时,就会调用这个工厂来获取早期引用。
Spring 通过 三级缓存 和 提前暴露未完全初始化的对象引用 的机制来解决单例作用域 Bean 的 sette注入方式的循环依赖问题。
假设存在两个相互依赖的单例Bean:BeanA 依赖 BeanB,同时 BeanB 也依赖 BeanA。当Spring容器启动时,它会按照以下流程处理:
第一步:创建
BeanA的实例并提前暴露工厂。
Spring首先调用BeanA的构造函数进行实例化,此时得到一个原始对象(尚未填充属性)。紧接着,Spring会将一个特殊的ObjectFactory工厂对象存入第三级缓存(singletonFactories)。这个工厂的使命是:当其他Bean需要引用BeanA时,它能动态返回当前这个半成品的BeanA(可能是原始对象,也可能是为应对AOP而提前生成的代理对象)。此时BeanA的状态是"已实例化但未初始化",像一座刚搭好钢筋骨架的大楼。
第二步:填充
BeanA的属性时触发BeanB的创建。
Spring开始为BeanA注入属性,发现它依赖BeanB。于是容器转向创建BeanB,同样先调用其构造函数实例化,并将BeanB对应的ObjectFactory工厂存入三级缓存。至此,三级缓存中同时存在BeanA和BeanB的工厂,它们都代表未完成初始化的半成品。
第三步:
BeanB属性注入时发现循环依赖。
当Spring试图填充BeanB的属性时,检测到它需要注入BeanA。此时容器启动依赖查找:
- 在一级缓存(存放完整Bean)中未找到
BeanA; - 在二级缓存(存放已暴露的早期引用)中同样未命中;
- 最终在三级缓存中定位到
BeanA的工厂。
Spring立即调用该工厂的getObject()方法。这个方法会执行关键决策:若BeanA需要AOP代理,则动态生成代理对象(即使BeanA还未初始化);若无需代理,则直接返回原始对象。得到的这个早期引用(可能是代理)被放入二级缓存(earlySingletonObjects),同时从三级缓存清理工厂条目。最后,Spring将这个早期引用注入到BeanB的属性中。至此,BeanB成功持有BeanA的引用——尽管BeanA此时仍是个半成品。
第四步:完成
BeanB的生命周期。
BeanB获得所有依赖后,Spring执行其初始化方法(如@PostConstruct),将其转化为完整可用的Bean。随后,BeanB被提升至一级缓存(singletonObjects),二级和三级缓存中关于BeanB的临时条目均被清除。此时BeanB已准备就绪,可被其他对象使用。
第五步:回溯完成
BeanA的构建。
随着BeanB创建完毕,流程回溯到最初中断的BeanA属性注入环节。Spring将已完备的BeanB实例注入BeanA,接着执行BeanA的初始化方法。这里有个精妙细节:若之前为BeanA生成过早期代理,Spring会直接复用二级缓存中的代理对象作为最终Bean,而非重复创建。最终,完全初始化的BeanA(可能是原始对象或代理)入驻一级缓存,其早期引用从二级缓存移除。至此循环闭环完成,两个Bean皆可用。
三级缓存的设计的精髓:
- 三级缓存工厂(
singletonFactories)负责在实例化后立刻暴露对象生成能力,兼顾AOP代理的提前生成; - 二级缓存(
earlySingletonObjects)临时存储已确定的早期引用,避免重复生成代理; - 一级缓存(
singletonObjects)最终交付完整Bean。
整个机制通过中断初始化流程、逆向注入半成品、延迟代理生成三大策略,将循环依赖的死结转化为有序的接力协作。
值得注意的是,此方案仅适用于Setter/Field注入的单例Bean;构造器注入因必须在实例化前获得依赖,仍会导致无解的死锁。
# 如何使用spring实现事务?
声明式事务管理
使用@Transactional注解来管理事务比较简单,示例如下:
@Service
public class TransactionDemo {
@Transactional
public void declarativeUpdate() {
updateOperation1();
updateOperation2();
}
}
这样的写法相当于在进入declarativeUpdate()方法前,使用BEGIN开启了事务,在执行完方法后,使用COMMIT提交事务。
也可以将@Transactional注解放在类上面,表示类中所有的public方法都开启了事务:
@Service
@Transactional
public class TransactionDemo {
public void declarativeUpdate() {
updateOperation1();
updateOperation2();
}
// 其他public方法...
}
编程式事务管理
相比之下,使用编程式事务要略微复杂一些。
编程式事务管理是通过编写代码来显式地管理事务。这种方式提供了更多的控制,但也会使业务代码变得复杂。
Spring提供了TransactionTemplate类来简化编程式事务管理。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.TransactionStatus;
import org.springframework.transaction.support.TransactionCallbackWithoutResult;
import org.springframework.transaction.support.TransactionTemplate;
@Service
public class UserService {
@Autowired
private UserDao userDao;
@Autowired
private TransactionTemplate transactionTemplate;
public void addUser(User user) {
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
@Override
protected void doInTransactionWithoutResult(TransactionStatus status) {
userDao.insert(user);
// 其他数据库操作
}
});
}
}
声明式事务 vs 编程式事务

在合适的场景使用合适的方式非常重要,在一些场景下,当对事务操作非常频繁,特别是在递归、外部通讯等耗时的场景中使用事务,很有可能就会引发长事务,那么应该考虑将非事务的部分放在前面执行,最后在写入数据环节时再开启事务。
# 介绍事务传播模型有哪些?
Spring中规定了7种类型的事务传播特性:

# springboot常用注解有哪些?
Bean 相关:
@Component:将一个类标识为 Spring 组件(Bean),可以被 Spring 容器自动检测和注册。通用注解,适用于任何层次的组件。@ComponentScan:自动扫描指定包及其子包中的 Spring 组件。@Controller:标识控制层组件,实际上是 @Component 的一个特化,用于表示 Web 控制器。处理 HTTP 请求并返回视图或响应数据。@RestController:是 @Controller 和 @ResponseBody 的结合,返回的对象会自动序列化为 JSON 或 XML,并写入 HTTP 响应体中。@Repository:标识持久层组件(DAO 层),实际上是 @Component 的一个特化,用于表示数据访问组件。常用于与数据库交互。@Bean:方法注解,用于修饰方法,主要功能是将修饰方法的返回对象添加到 Spring 容器中,使得其他组件可以通过依赖注入的方式使用这个对象。
依赖注入:
@Autowired:用于自动注入依赖对象,Spring 框架提供的注解。@Resource:按名称自动注入依赖对象(也可以按类型,但默认按名称),JDK 提供注解。@Qualifier:与 @Autowired 一起使用,用于指定要注入的 Bean 的名称。当存在多个相同类型的 Bean 时,可以使用 @Qualifier 来指定注入哪一个。
读取配置:
@Value:用于注入属性值,通常从配置文件中获取。标注在字段上,并指定属性值的来源(如配置文件中的某个属性)。@ConfigurationProperties:用于将配置属性绑定到一个实体类上。通常用于从配置文件中读取属性值并绑定到类的字段上。
Web相关:
@RequestMapping:用于映射 HTTP 请求到处理方法上,支持 GET、POST、PUT、DELETE 等请求方法。可以标注在类或方法上。标注在类上时,表示类中的所有响应请求的方法都是以该类路径为父路径。@GetMapping、@PostMapping、@PutMapping、@DeleteMapping:分别用于映射 HTTP GET、POST、PUT、DELETE 请求到处理方法上。它们是 @RequestMapping 的特化,分别对应不同的 HTTP 请求方法。
其他常用注解:
@Transactional:声明事务管理。标注在类或方法上,指定事务的传播行为、隔离级别等。@Scheduled:声明一个方法需要定时执行。标注在方法上,并指定定时执行的规则(如每隔一定时间执行一次)。
# 介绍NIO BIO AIO?
- BIO(blocking IO):就是传统的 java.io 包,它是基于流模型实现的,交互的方式是同步、阻塞方式,也就是说在读入输入流或者输出流时,在读写动作完成之前,线程会一直阻塞在那里,它们之间的调用是可靠的线性顺序。优点是代码比较简单、直观;缺点是 IO 的效率和扩展性很低,容易成为应用性能瓶颈。
- NIO(non-blocking IO) :Java 1.4 引入的 java.nio 包,提供了 Channel、Selector、Buffer 等新的抽象,可以构建多路复用的、同步非阻塞 IO 程序,同时提供了更接近操作系统底层高性能的数据操作方式。
- AIO(Asynchronous IO) :是 Java 1.7 之后引入的包,是 NIO 的升级版本,提供了异步非堵塞的 IO 操作方式,所以人们叫它 AIO(Asynchronous IO),异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
# Redis
# redis高级数据结构的使用场景
Redis 提供了丰富的数据类型,常见的有五种数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)。
随着 Redis 版本的更新,后面又支持了四种数据类型:BitMap(2.2 版新增)、HyperLogLog(2.8 版新增)、GEO(3.2 版新增)、Stream(5.0 版新增)。Redis 五种数据类型的应用场景:
- String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
- List 类型的应用场景:消息队列(但是有两个问题:1. 生产者需要自行实现全局唯一 ID;2. 不能以消费组形式消费数据)等。
- Hash 类型:缓存对象、购物车等。
- Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
- Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
Redis 后续版本又支持四种数据类型,它们的应用场景如下:
- BitMap(2.2 版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
- HyperLogLog(2.8 版新增):海量数据基数统计的场景,比如百万级网页 UV 计数等;
- GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
- Stream(5.0 版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
# linux
# linux常用命令有哪些?
- 文件相关(mv mkdir cd ls)
- 进程相关( ps top netstate )
- 权限相关(chmod chown useradd groupadd)
- 网络相关(netstat ip addr)
- 测试相关(测试网络连通性:ping 测试端口连通性:telnet)
# kill -9 9的意义是什么,如何做到强制终止线程
kill -9 是一个Linux/Unix系统中的命令,用于向进程发送信号。-9代表的是SIGKILL信号,这是一种无法被捕获、忽略或重定义的信号,用于立即终止一个进程。当使用kill -9命令时,操作系统会立即停止目标进程,不会给进程任何清理或释放资源的机会。
kill命令是针对进程的,而不是针对线程的。要终止一个线程,你需要知道该线程所属的进程ID(PID)和线程ID(TID)。
以下是几种终止线程的方法:
- 使用
kill命令终止整个进程:如果你想要终止包含特定线程的整个进程,可以使用kill命令发送SIGKILL信号给进程。
kill -9 <PID>
- 使用
kill命令结合ps和grep命令查找线程ID:如果你只知道线程的名称或某些特征,可以使用ps和grep命令来查找线程ID,然后使用kill命令终止线程。
ps -eLf | grep <thread_name_or_feature> | grep -v grep | awk '{print $2}' | xargs kill -9
这里的<thread_name_or_feature>是线程的名称或某些特征。
# 算法
- 讲一下二叉树最近公共父节点算法
对了,最新的互联网大厂后端面经都会在公众号首发,别忘记关注哦!!如果你想加入百人技术交流群,扫码下方二维码回复「加群」。
