# 唯品会 Java 面试

大家好,我是小林。
唯品会开发岗的校招薪资范围大概是 17k-21k x 14,年薪 24w~29w,不过感觉今年唯品会校招没有怎么招开发岗的人,看到面试的人不算多,可能也是因为公司业务趋向稳定,没有新的增长空间,就没去扩从开发人员。
有位面了唯品会后端开发岗的同学被拷打了一小时,面试官真的很nice,我感觉我都没答出来,说了这辈子最多的不好意思,但是面试官真的很好很好,每一题都会适当引导我,可惜自己太菜,有些时候 get 不到面试官的点。
这次一起来看看他的面经,主要是拷打了Java集合、Java 并发、网络、场景、算法这些内容。

# Java
# 常见的Map及哪些是线程安全的?
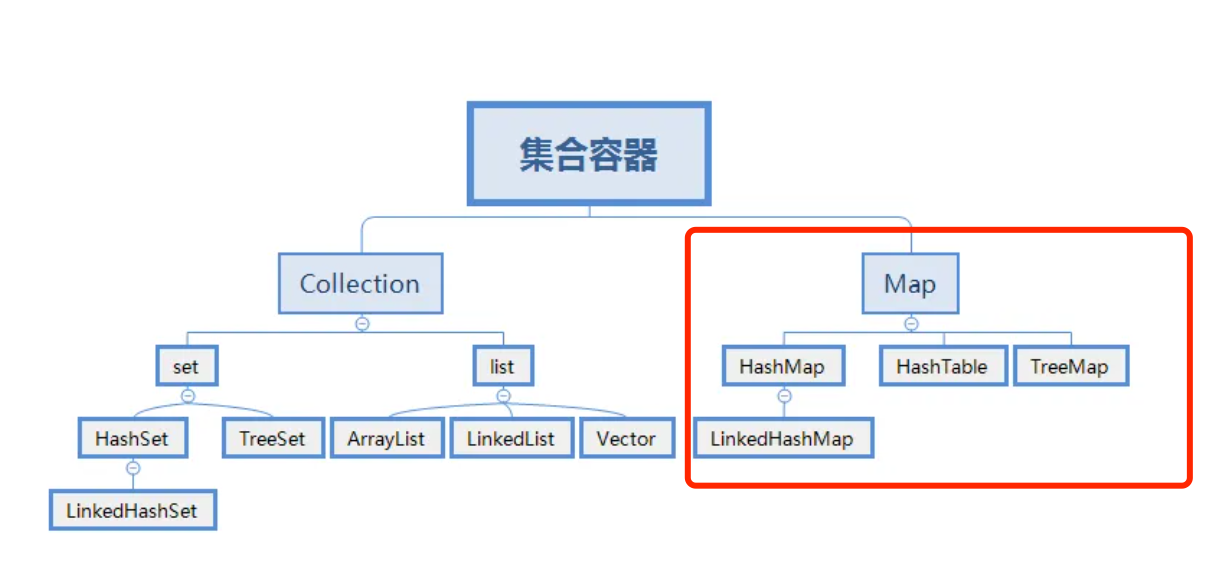
常见的Map集合(非线程安全):
HashMap是基于哈希表实现的Map,它根据键的哈希值来存储和获取键值对,JDK 1.8中是用数组+链表+红黑树来实现的。HashMap是非线程安全的,在多线程环境下,当多个线程同时对HashMap进行操作时,可能会导致数据不一致或出现死循环等问题。比如在扩容时,多个线程可能会同时修改哈希表的结构,从而破坏数据的完整性。LinkedHashMap继承自HashMap,它在HashMap的基础上,使用双向链表维护了键值对的插入顺序或访问顺序,使得迭代顺序与插入顺序或访问顺序一致。由于它继承自HashMap,在多线程并发访问时,同样会出现与HashMap类似的线程安全问题。TreeMap是基于红黑树实现的Map,它可以对键进行排序,默认按照自然顺序排序,也可以通过指定的比较器进行排序。TreeMap是非线程安全的,在多线程环境下,如果多个线程同时对TreeMap进行插入、删除等操作,可能会破坏红黑树的结构,导致数据不一致或程序出现异常。
常见的Map集合(线程安全):
Hashtable是早期 Java 提供的线程安全的Map实现,它的实现方式与HashMap类似,但在方法上使用了synchronized关键字来保证线程安全。通过在每个可能修改Hashtable状态的方法上加上synchronized关键字,使得在同一时刻,只能有一个线程能够访问Hashtable的这些方法,从而保证了线程安全。ConcurrentHashMap在 JDK 1.8 以前采用了分段锁等技术来提高并发性能。在ConcurrentHashMap中,将数据分成多个段(Segment),每个段都有自己的锁。在进行插入、删除等操作时,只需要获取相应段的锁,而不是整个Map的锁,这样可以允许多个线程同时访问不同的段,提高了并发访问的效率。在 JDK 1.8 以后是通过 volatile + CAS 或者 synchronized 来保证线程安全的
# 如何对map进行快速遍历?
- 使用for-each循环和entrySet()方法:这是一种较为常见和简洁的遍历方式,它可以同时获取
Map中的键和值
import java.util.HashMap;
import java.util.Map;
public class MapTraversalExample {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("key1", 1);
map.put("key2", 2);
map.put("key3", 3);
// 使用for-each循环和entrySet()遍历Map
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());
}
}
}
- 使用for-each循环和keySet()方法:如果只需要遍历
Map中的键,可以使用keySet()方法,这种方式相对简单,性能也较好。
import java.util.HashMap;
import java.util.Map;
public class MapTraversalExample {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("key1", 1);
map.put("key2", 2);
map.put("key3", 3);
// 使用for-each循环和keySet()遍历Map的键
for (String key : map.keySet()) {
System.out.println("Key: " + key + ", Value: " + map.get(key));
}
}
}
- 使用迭代器:通过获取Map的entrySet()或keySet()的迭代器,也可以实现对Map的遍历,这种方式在需要删除元素等操作时比较有用。
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
public class MapTraversalExample {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("key1", 1);
map.put("key2", 2);
map.put("key3", 3);
// 使用迭代器遍历Map
Iterator<Entry<String, Integer>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Entry<String, Integer> entry = iterator.next();
System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());
}
}
}
- 使用 Lambda 表达式和forEach()方法:在 Java 8 及以上版本中,可以使用 Lambda 表达式和
forEach()方法来遍历Map,这种方式更加简洁和函数式。
import java.util.HashMap;
import java.util.Map;
public class MapTraversalExample {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("key1", 1);
map.put("key2", 2);
map.put("key3", 3);
// 使用Lambda表达式和forEach()方法遍历Map
map.forEach((key, value) -> System.out.println("Key: " + key + ", Value: " + value));
}
}
- 使用Stream API:Java 8 引入的
Stream API也可以用于遍历Map,可以将Map转换为流,然后进行各种操作。
import java.util.HashMap;
import java.util.Map;
import java.util.stream.Collectors;
public class MapTraversalExample {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("key1", 1);
map.put("key2", 2);
map.put("key3", 3);
// 使用Stream API遍历Map
map.entrySet().stream()
.forEach(entry -> System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue()));
// 还可以进行其他操作,如过滤、映射等
Map<String, Integer> filteredMap = map.entrySet().stream()
.filter(entry -> entry.getValue() > 1)
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
System.out.println(filteredMap);
}
}
# 常见的List?有没有线程安全的List?
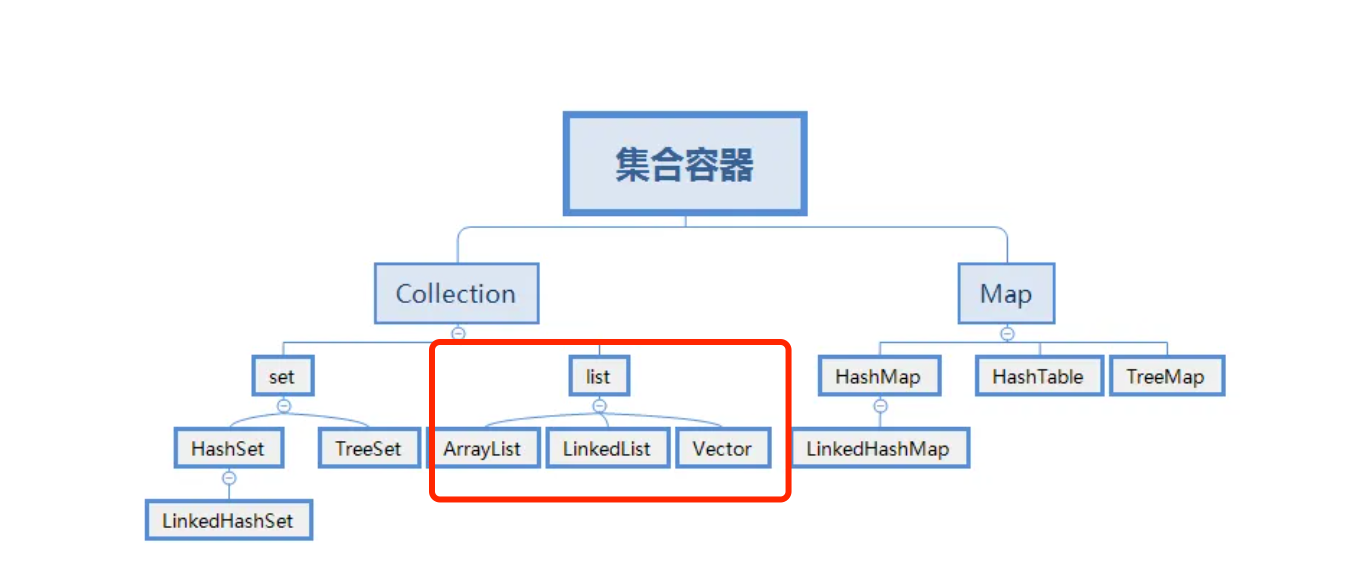
常见的List集合(非线程安全):
ArrayList基于动态数组实现,它允许快速的随机访问,即通过索引访问元素的时间复杂度为 O (1)。在添加和删除元素时,如果操作位置不是列表末尾,可能需要移动大量元素,性能相对较低。适用于需要频繁随机访问元素,而对插入和删除操作性能要求不高的场景,如数据的查询和展示等。LinkedList基于双向链表实现,在插入和删除元素时,只需修改链表的指针,不需要移动大量元素,时间复杂度为 O (1)。但随机访问元素时,需要从链表头或链表尾开始遍历,时间复杂度为 O (n)。适用于需要频繁进行插入和删除操作的场景,如队列、栈等数据结构的实现,以及需要在列表中间频繁插入和删除元素的情况。
常见的List集合(线程安全):
Vector和ArrayList类似,也是基于数组实现。Vector中的方法大多是同步的,这使得它在多线程环境下可以保证数据的一致性,但在单线程环境下,由于同步带来的开销,性能会略低于ArrayList。CopyOnWriteArrayList在对列表进行修改(如添加、删除元素)时,会创建一个新的底层数组,将修改操作应用到新数组上,而读操作仍然在原数组上进行,这样可以保证读操作不会被写操作阻塞,实现了读写分离,提高了并发性能。适用于读操作远远多于写操作的并发场景,如事件监听列表等,在这种场景下可以避免大量的锁竞争,提高系统的性能和响应速度。
# list可以一边遍历一边修改元素吗?
在 Java 中,List在遍历过程中是否可以修改元素取决于遍历方式和具体的List实现类,以下是几种常见情况:
- 使用普通for循环遍历:可以在遍历过程中修改元素,只要修改的索引不超出
List的范围即可。
import java.util.ArrayList;
import java.util.List;
public class ListTraversalAndModification {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
// 使用普通for循环遍历并修改元素
for (int i = 0; i < list.size(); i++) {
list.set(i, list.get(i) * 2);
}
System.out.println(list);
}
}
- 使用foreach循环遍历:一般不建议在
foreach循环中直接修改正在遍历的List元素,因为这可能会导致意外的结果或ConcurrentModificationException异常。在foreach循环中修改元素可能会破坏迭代器的内部状态,因为foreach循环底层是基于迭代器实现的,在遍历过程中修改集合结构,会导致迭代器的预期结构和实际结构不一致。
import java.util.ArrayList;
import java.util.List;
public class ListTraversalAndModification {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
// 使用foreach循环遍历并尝试修改元素,会抛出ConcurrentModificationException异常
for (Integer num : list) {
list.set(list.indexOf(num), num * 2);
}
System.out.println(list);
}
}
- 使用迭代器遍历:可以使用迭代器的
remove方法来删除元素,但如果要修改元素的值,需要通过迭代器的set方法来进行,而不是直接通过List的set方法,否则也可能会抛出ConcurrentModificationException异常。
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ListTraversalAndModification {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
// 使用迭代器遍历并修改元素
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {
Integer num = iterator.next();
if (num == 2) {
// 使用迭代器的set方法修改元素
iterator.set(4);
}
}
System.out.println(list);
}
}
对于线程安全的List,如CopyOnWriteArrayList,由于其采用了写时复制的机制,在遍历的同时可以进行修改操作,不会抛出ConcurrentModificationException异常,但可能会读取到旧的数据,因为修改操作是在新的副本上进行的。
# list如何快速删除某个指定下标的元素?
ArrayList提供了remove(int index)方法来删除指定下标的元素,该方法在删除元素后,会将后续元素向前移动,以填补被删除元素的位置。如果删除的是列表末尾的元素,时间复杂度为 O (1);如果删除的是列表中间的元素,时间复杂度为 O (n),n 为列表中元素的个数,因为需要移动后续的元素。示例代码如下:
import java.util.ArrayList;
import java.util.List;
public class ArrayListRemoveExample {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
// 删除下标为1的元素
list.remove(1);
System.out.println(list);
}
}
LinkedList的remove(int index)方法也可以用来删除指定下标的元素。它需要先遍历到指定下标位置,然后修改链表的指针来删除元素。时间复杂度为 O (n),n 为要删除元素的下标。不过,如果已知要删除的元素是链表的头节点或尾节点,可以直接通过修改头指针或尾指针来实现删除,时间复杂度为 O (1)。示例代码如下:
import java.util.LinkedList;
import java.util.List;
public class LinkedListRemoveExample {
public static void main(String[] args) {
List<Integer> list = new LinkedList<>();
list.add(1);
list.add(2);
list.add(3);
// 删除下标为1的元素
list.remove(1);
System.out.println(list);
}
}
opyOnWriteArrayList的remove方法同样可以删除指定下标的元素。由于CopyOnWriteArrayList在写操作时会创建一个新的数组,所以删除操作的时间复杂度取决于数组的复制速度,通常为 O (n),n 为数组的长度。但在并发环境下,它的删除操作不会影响读操作,具有较好的并发性能。示例代码如下:
import java.util.concurrent.CopyOnWriteArrayList;
public class CopyOnWriteArrayListRemoveExample {
public static void main(String[] args) {
CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList<>();
list.add(1);
list.add(2);
list.add(3);
// 删除下标为1的元素
list.remove(1);
System.out.println(list);
}
}
# 常见的队列有哪些及应用场景?
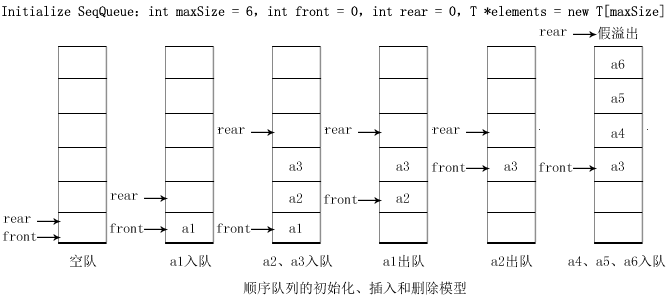
- 顺序队列是利用一组连续的存储单元依次存放从队头到队尾的元素,同时设置两个指针,一个指向队头元素的位置,称为队头指针;另一个指向队尾元素的下一个位置,称为队尾指针。实现简单,空间利用率低,当队尾指针到达数组末尾时,即使前面有空闲空间,也可能无法继续插入元素,造成假溢出。一些简单的、对队列操作不太频繁且数据量相对较小的场景,如学校食堂打饭排队系统,可简单模拟学生排队打饭的过程,新学生在队尾加入,打到饭的学生从队头离开。
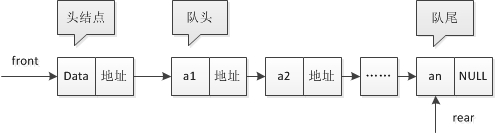
- 链式队列是通过链表来实现的队列,每个节点包含数据域和指针域,指针域指向下一个节点。队头指针指向链表的头节点,队尾指针指向链表的尾节点。插入和删除操作在链表的两端进行,不需要移动元素,操作效率高,可动态分配内存,不存在空间溢出问题,但需要额外的指针空间来存储节点之间的链接关系。常用于处理数据量不确定、需要频繁进行插入和删除操作的场景,如操作系统中的进程调度,新进程可以随时在队尾加入等待队列,就绪的进程从队头取出执行。
- 循环队列是把顺序队列的存储空间想象成一个首尾相接的圆环,当队尾指针到达数组末尾时,若数组头部还有空闲空间,则将队尾指针重新指向数组头部,继续插入元素。充分利用了数组的空间,避免了顺序队列中的假溢出问题,提高了空间利用率,但实现相对复杂一些,需要处理队头和队尾指针在循环时的特殊情况。常用于数据缓冲区的管理,如音频、视频数据的缓冲,数据以循环的方式存入缓冲区,消费端从队头取出数据进行处理,保证数据的连续和稳定。
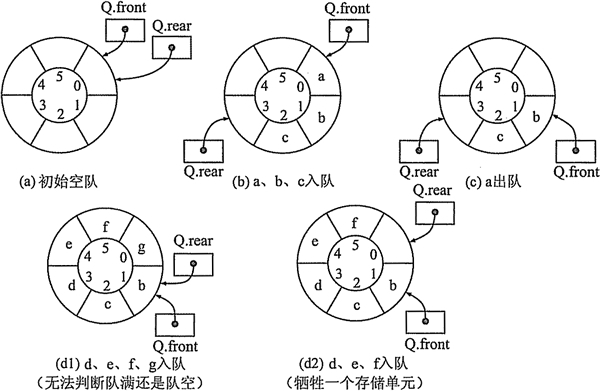
- 双端队列是一种特殊的队列,它允许在队列的两端进行插入和删除操作,既有队头指针又有队尾指针,两端都可以作为队头或队尾进行操作。具有很高的灵活性,可在两端快速插入和删除元素,支持多种操作模式,但实现相对复杂,需要更多的代码来维护两端的操作逻辑。在一些需要频繁在两端进行数据操作的场景中非常有用,如在浏览器的页面浏览历史记录中,用户可以向前和向后浏览页面,新访问的页面可以从队头或队尾插入,浏览过的页面可以从两端删除。
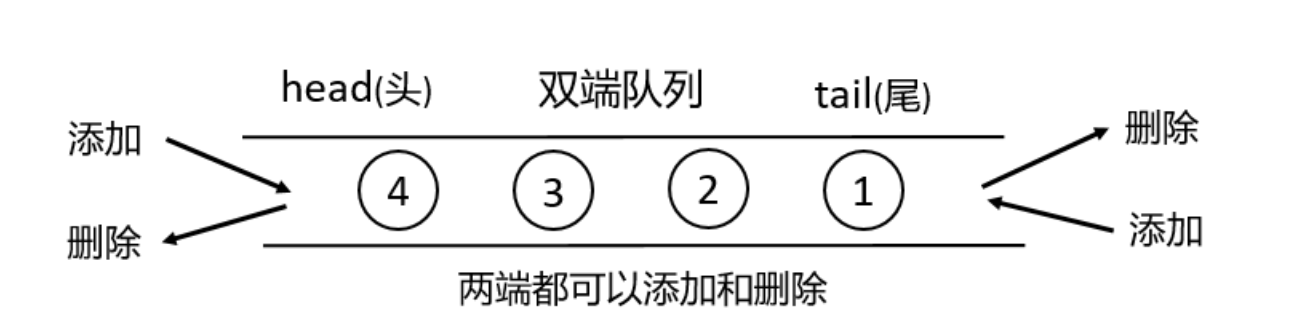
- 优先级队列中的每个元素都有一个优先级,在插入和删除元素时,会根据元素的优先级来进行操作,优先级高的元素先出队。通常使用堆等数据结构来实现,以保证高效的插入和删除操作。能够快速获取优先级最高(或最低)的元素并进行处理,插入和删除操作的时间复杂度通常为 O (log n),其中 n 是队列中的元素个数。在任务调度系统中,不同任务可能具有不同的优先级,优先级高的任务需要优先执行,如操作系统中的进程调度,实时性要求高的进程具有较高的优先级,会优先被调度执行。
# juc包下你常用的类?
线程池相关:
ThreadPoolExecutor:最核心的线程池类,用于创建和管理线程池。通过它可以灵活地配置线程池的参数,如核心线程数、最大线程数、任务队列等,以满足不同的并发处理需求。Executors:线程池工厂类,提供了一系列静态方法来创建不同类型的线程池,如newFixedThreadPool(创建固定线程数的线程池)、newCachedThreadPool(创建可缓存线程池)、newSingleThreadExecutor(创建单线程线程池)等,方便开发者快速创建线程池。
并发集合类:
ConcurrentHashMap:线程安全的哈希映射表,用于在多线程环境下高效地存储和访问键值对。它采用了分段锁等技术,允许多个线程同时访问不同的段,提高了并发性能,在高并发场景下比传统的Hashtable性能更好。CopyOnWriteArrayList:线程安全的列表,在对列表进行修改操作时,会创建一个新的底层数组,将修改操作应用到新数组上,而读操作仍然可以在旧数组上进行,从而实现了读写分离,提高了并发读的性能,适用于读多写少的场景。
同步工具类:
CountDownLatch:允许一个或多个线程等待其他一组线程完成操作后再继续执行。它通过一个计数器来实现,计数器初始化为线程的数量,每个线程完成任务后调用countDown方法将计数器减一,当计数器为零时,等待的线程可以继续执行。常用于多个线程完成各自任务后,再进行汇总或下一步操作的场景。CyclicBarrier:让一组线程互相等待,直到所有线程都到达某个屏障点后,再一起继续执行。与CountDownLatch不同的是,CyclicBarrier可以重复使用,当所有线程都通过屏障后,计数器会重置,可以再次用于下一轮的等待。适用于多个线程需要协同工作,在某个阶段完成后再一起进入下一个阶段的场景。Semaphore:信号量,用于控制同时访问某个资源的线程数量。它维护了一个许可计数器,线程在访问资源前需要获取许可,如果有可用许可,则获取成功并将许可计数器减一,否则线程需要等待,直到有其他线程释放许可。常用于控制对有限资源的访问,如数据库连接池、线程池中的线程数量等。
原子类:
AtomicInteger:原子整数类,提供了对整数类型的原子操作,如自增、自减、比较并交换等。通过硬件级别的原子指令来保证操作的原子性和线程安全性,避免了使用锁带来的性能开销,在多线程环境下对整数进行计数、状态标记等操作非常方便。AtomicReference:原子引用类,用于对对象引用进行原子操作。可以保证在多线程环境下,对对象的更新操作是原子性的,即要么全部成功,要么全部失败,不会出现数据不一致的情况。常用于实现无锁数据结构或需要对对象进行原子更新的场景。
# 3个线程并发执行,1个线程等待这三个线程全部执行完在执行,怎么实现?
可以使用 CountDownLatch 来实现 3 个线程并发执行,另一个线程等待这三个线程全部执行完再执行的需求。以下是具体的实现步骤:
- 创建一个
CountDownLatch对象,并将计数器初始化为 3,因为有 3 个线程需要等待。 - 创建 3 个并发执行的线程,在每个线程的任务结束时调用
countDown方法将计数器减 1。 - 创建第 4 个线程,使用
await方法等待计数器为 0,即等待其他 3 个线程完成任务。
import java.util.concurrent.CountDownLatch;
public class CountDownLatchExample {
public static void main(String[] args) {
// 创建一个 CountDownLatch,初始计数为 3
CountDownLatch latch = new CountDownLatch(3);
// 创建并启动 3 个并发线程
for (int i = 0; i < 3; i++) {
final int threadNumber = i + 1;
new Thread(() -> {
try {
System.out.println("Thread " + threadNumber + " is working.");
// 模拟线程执行任务
Thread.sleep((long) (Math.random() * 1000));
System.out.println("Thread " + threadNumber + " has finished.");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 任务完成后,计数器减 1
latch.countDown();
}
}).start();
}
// 创建并启动第 4 个线程,等待其他 3 个线程完成
new Thread(() -> {
try {
System.out.println("Waiting for other threads to finish.");
// 等待计数器为 0
latch.await();
System.out.println("All threads have finished, this thread starts to work.");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
代码解释:
- 首先,创建了一个
CountDownLatch对象latch,并将其初始计数设置为 3。 - 然后,使用
for循环创建并启动 3 个线程。每个线程会执行一些工作(这里使用Thread.sleep模拟),在工作完成后,会调用latch.countDown()方法,将latch的计数减 1。 - 最后,创建第 4 个线程。这个线程在开始时调用
latch.await()方法,它会阻塞,直到latch的计数为 0,即前面 3 个线程都调用了countDown()方法。一旦计数为 0,该线程将继续执行后续任务。
# 单例模型既然已经用了synchronized,为什么还要在加volatile?
使用 synchronized 和 volatile 一起,可以创建一个既线程安全又能正确初始化的单例模式,避免了多线程环境下的各种潜在问题。这是一种比较完善的线程安全的单例模式实现方式,尤其适用于高并发环境。
public class Singleton {
private static volatile Singleton instance;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
synchronized 关键字的作用用于确保在多线程环境下,只有一个线程能够进入同步块(这里是 synchronized (Singleton.class))。在创建单例对象时,通过 synchronized 保证了创建过程的线程安全性,避免多个线程同时创建多个单例对象。
volatile 确保了对象引用的可见性和创建过程的有序性,避免了由于指令重排序而导致的错误。
instance = new Singleton(); 这行代码并不是一个原子操作,它实际上可以分解为以下几个步骤:
- 分配内存空间。
- 实例化对象。
- 将对象引用赋值给
instance。
由于 Java 内存模型允许编译器和处理器对指令进行重排序,在没有 volatile 的情况下,可能会出现重排序,例如先将对象引用赋值给 instance,但对象的实例化操作尚未完成。
这样,其他线程在检查 instance == null 时,会认为单例已经创建,从而得到一个未完全初始化的对象,导致错误。
volatile 可以保证变量的可见性和禁止指令重排序。它确保对 instance 的修改对所有线程都是可见的,并且保证了上述三个步骤按顺序执行,避免了在单例创建过程中因指令重排序而导致的问题。
# 场景
# 常见的限流算法你知道哪些??
- 滑动窗口限流算法是对固定窗口限流算法的改进,有效解决了窗口切换时可能会产生两倍于阈值流量请求的问题。
- 漏桶限流算法能够对流量起到整流的作用,让随机不稳定的流量以固定的速率流出,但是不能解决流量突发的问题。
- 令牌桶算法作为漏斗算法的一种改进,除了能够起到平滑流量的作用,还允许一定程度的流量突发。
固定窗口限流算法
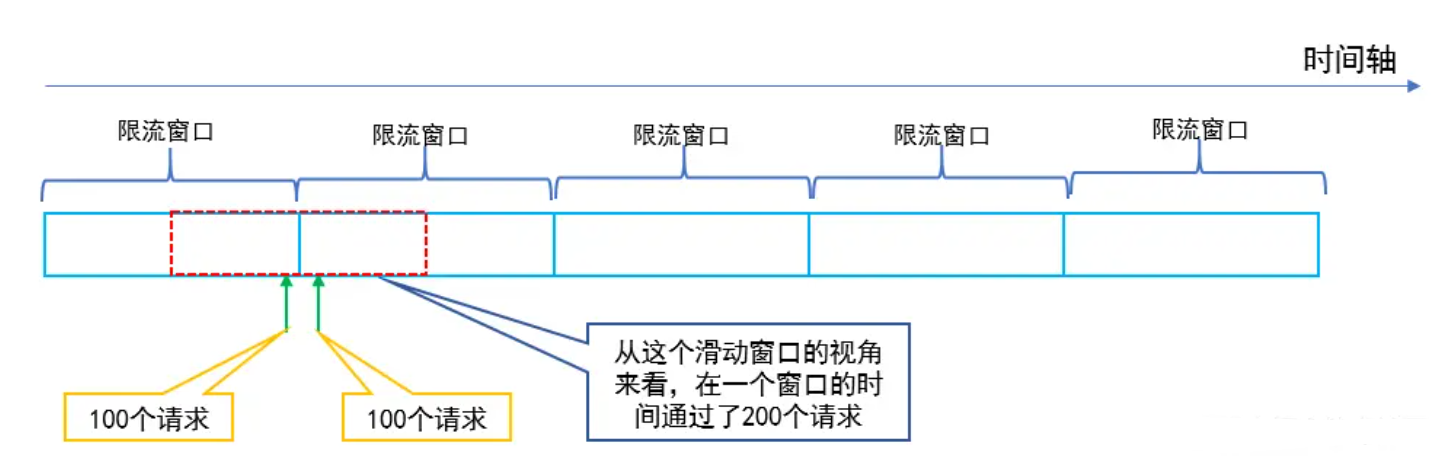
固定窗口限流算法就是对一段固定时间窗口内的请求进行计数,如果请求数超过了阈值,则舍弃该请求;如果没有达到设定的阈值,则接受该请求,且计数加1。当时间窗口结束时,重置计数器为0。
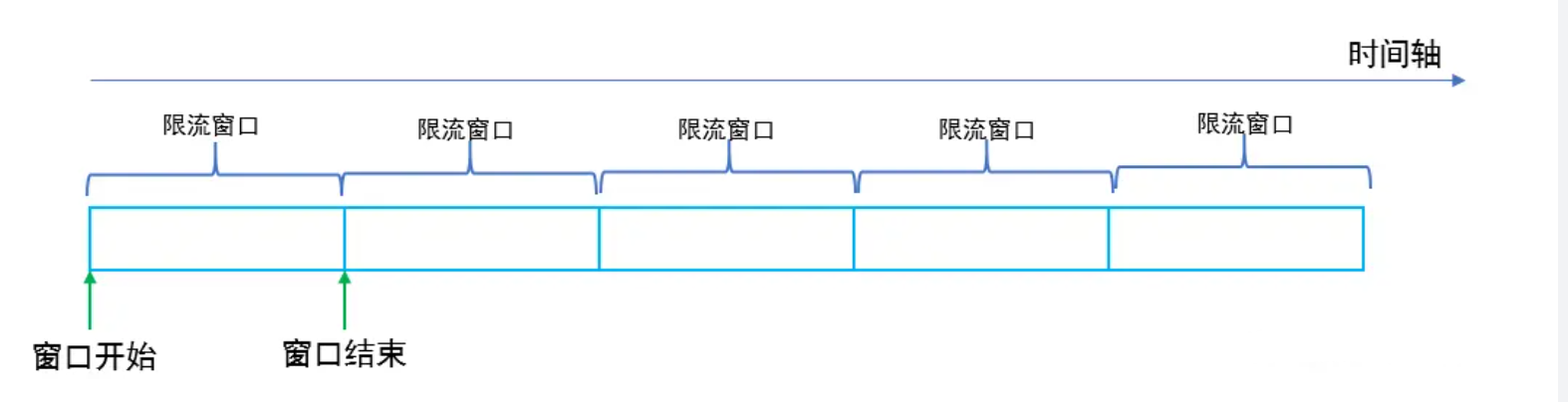
固定窗口限流优点是实现简单,但是会有“流量吐刺”的问题,假设窗口大小为1s,限流大小为100,然后恰好在某个窗口的第999ms来了100个请求,窗口前期没有请求,所以这100个请求都会通过。再恰好,下一个窗口的第1ms有来了100个请求,也全部通过了,那也就是在2ms之内通过了200个请求,而我们设定的阈值是100,通过的请求达到了阈值的两倍,这样可能会给系统造成巨大的负载压力。
滑动窗口限流算法
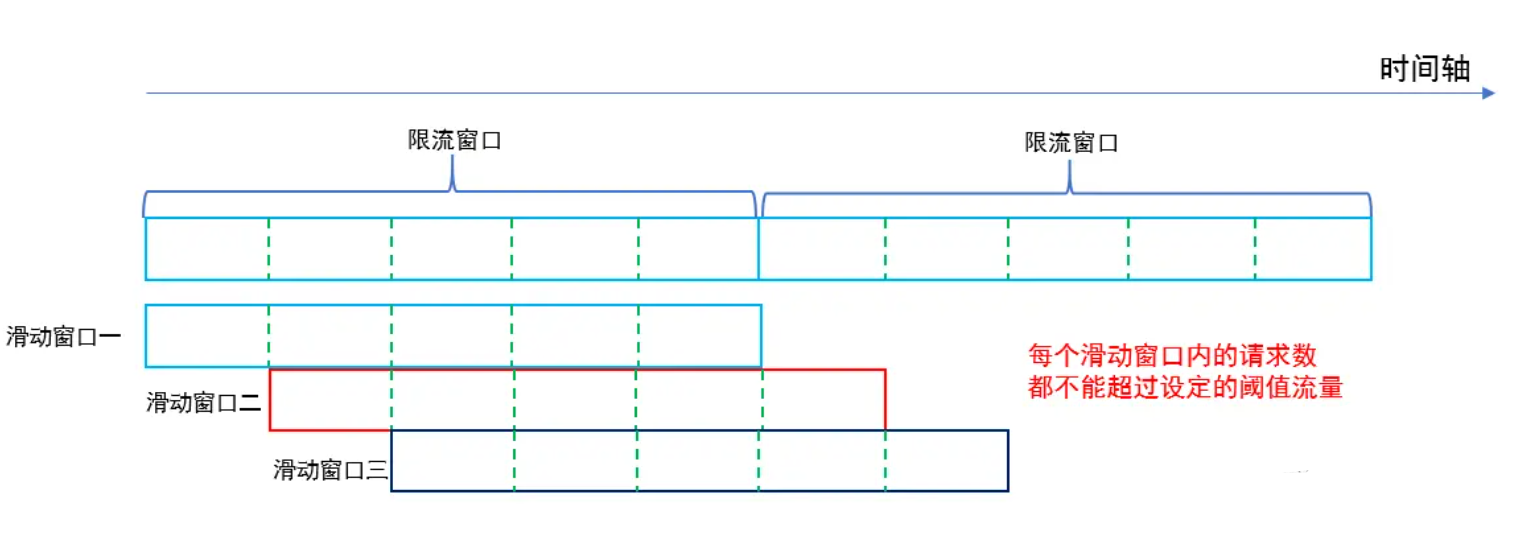
改进固定窗口缺陷的方法是采用滑动窗口限流算法,滑动窗口就是将限流窗口内部切分成一些更小的时间片,然后在时间轴上滑动,每次滑动,滑过一个小时间片,就形成一个新的限流窗口,即滑动窗口。然后在这个滑动窗口内执行固定窗口算法即可。
滑动窗口可以避免固定窗口出现的放过两倍请求的问题,因为一个短时间内出现的所有请求必然在一个滑动窗口内,所以一定会被滑动窗口限流。
漏桶限流算法
漏桶限流算法是模拟水流过一个有漏洞的桶进而限流的思路,如图。

水龙头的水先流入漏桶,再通过漏桶底部的孔流出。如果流入的水量太大,底部的孔来不及流出,就会导致水桶太满溢出去。
从系统的角度来看,我们不知道什么时候会有请求来,也不知道请求会以多大的速率来,这就给系统的安全性埋下了隐患。但是如果加了一层漏斗算法限流之后,就能够保证请求以恒定的速率流出。在系统看来,请求永远是以平滑的传输速率过来,从而起到了保护系统的作用。
使用漏桶限流算法,缺点有两个:
- 即使系统资源很空闲,多个请求同时到达时,漏桶也是慢慢地一个接一个地去处理请求,这其实并不符合人们的期望,因为这样就是在浪费计算资源。
- 不能解决流量突发的问题,假设漏斗速率是2个/秒,然后突然来了10个请求,受限于漏斗的容量,只有5个请求被接受,另外5个被拒绝。你可能会说,漏斗速率是2个/秒,然后瞬间接受了5个请求,这不就解决了流量突发的问题吗?不,这5个请求只是被接受了,但是没有马上被处理,处理的速度仍然是我们设定的2个/秒,所以没有解决流量突发的问题
令牌桶限流算法
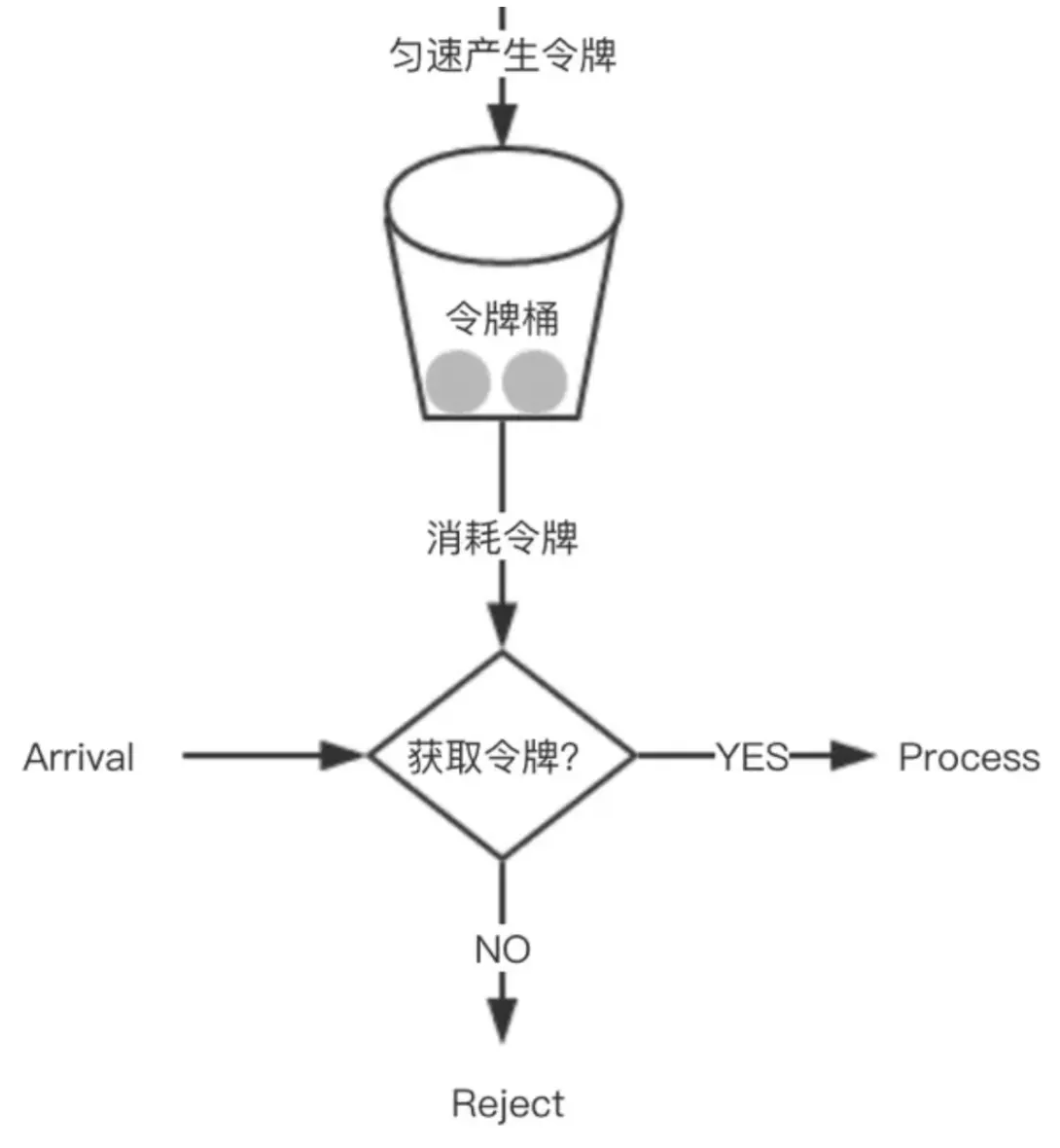
令牌桶是另一种桶限流算法,模拟一个特定大小的桶,然后向桶中以特定的速度放入令牌(token),请求到达后,必须从桶中取出一个令牌才能继续处理。如果桶中已经没有令牌了,那么当前请求就被限流。如果桶中的令牌放满了,令牌桶也会溢出。
放令牌的动作是持续不断进行的,如果桶中令牌数达到上限,则丢弃令牌,因此桶中可能一直持有大量的可用令牌。此时请求进来可以直接拿到令牌执行。比如设置 qps 为 100,那么限流器初始化完成 1 秒后,桶中就已经有 100 个令牌了,如果此前还没有请求过来,这时突然来了 100 个请求,该限流器可以抵挡瞬时的 100 个请求。由此可见,只有桶中没有令牌时,请求才会进行等待,最终表现的效果即为以一定的速率执行。令牌桶的示意图如下:
令牌桶限流算法综合效果比较好,能在最大程度利用系统资源处理请求的基础上,实现限流的目标,建议通常场景中优先使用该算法。
# 网络
# 第四次握手为什么需要等待TIME_WAIT?
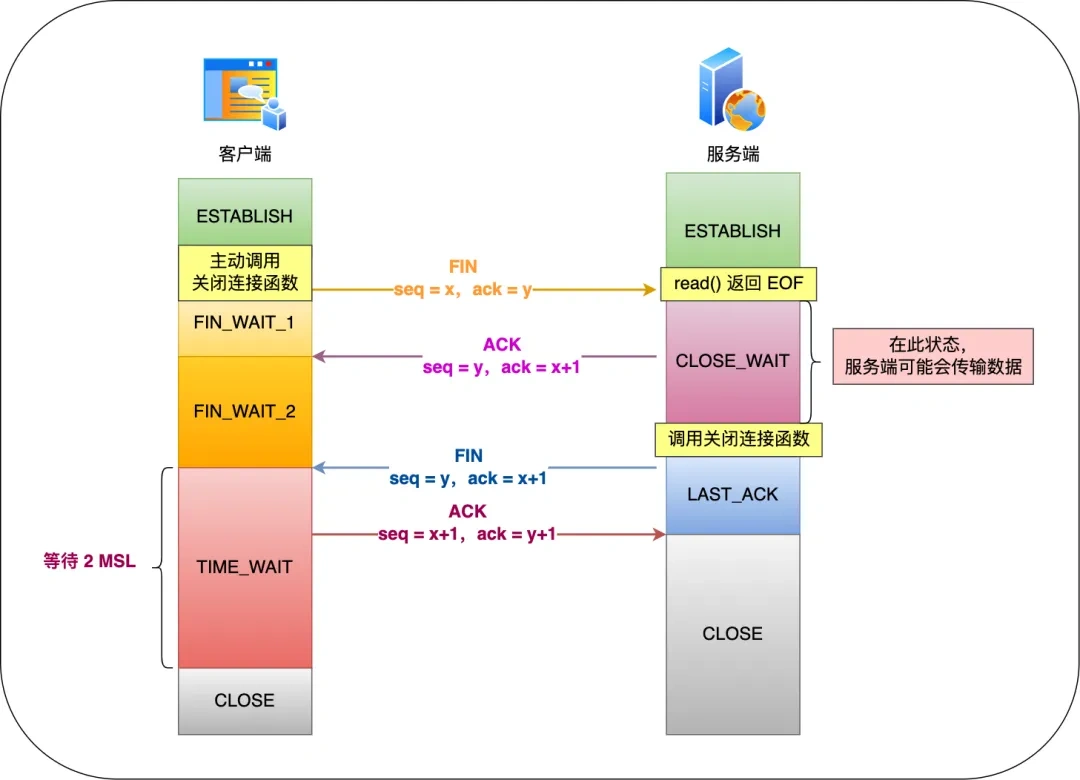
TIME_WAIT 状态的存在是为了确保网络连接的可靠关闭。只有主动发起关闭连接的一方(即主动关闭方)才会有 TIME_WAIT 状态。
TIME_WAIT 状态的需求主要有两个原因:
- 防止具有相同「四元组」的「旧」数据包被收到:在网络通信中,每个 TCP 连接都由源 IP 地址、源端口号、目标 IP 地址和目标端口号这四个元素唯一标识,称为「四元组」。当一方主动关闭连接后,进入 TIME_WAIT 状态,它仍然可以接收到一段时间内来自对方的延迟数据包。这是因为网络中可能存在被延迟传输的数据包,如果没有 TIME_WAIT 状态的存在,这些延迟数据包可能会被错误地传递给新的连接,导致数据混乱。通过保持 TIME_WAIT 状态,可以防止旧的数据包干扰新的连接。
- 保证「被动关闭连接」的一方能被正确关闭:当连接的被动关闭方接收到主动关闭方的 FIN 报文(表示关闭连接),它需要发送一个确认 ACK 报文给主动关闭方,以完成连接的关闭。然而,网络是不可靠的,ACK 报文可能会在传输过程中丢失。如果主动关闭方在收到 ACK 报文之前就关闭连接,被动关闭方将无法正常完成连接的关闭。TIME_WAIT 状态的存在确保了被动关闭方能够接收到最后的 ACK 报文,从而帮助其正常关闭连接。
# io多路复用你的理解?
IO多路复用是一种IO得处理方式,指的是复用一个线程,处理多个socket中的事件。能够资源复用,防止创建过多线程导致的上下文切换的开销。
我们熟悉的 select/poll/epoll 内核提供给用户态的多路复用系统调用,进程可以通过一个系统调用函数从内核中获取多个事件。
select/poll/epoll 是如何获取网络事件的呢?在获取事件时,先把所有连接(文件描述符)传给内核,再由内核返回产生了事件的连接,然后在用户态中再处理这些连接对应的请求即可。
select/poll/epoll 这是三个多路复用接口,都能实现 C10K 吗?接下来,我们分别说说它们。
select/poll
select 实现多路复用的方式是,将已连接的 Socket 都放到一个文件描述符集合,然后调用 select 函数将文件描述符集合拷贝到内核里,让内核来检查是否有网络事件产生,检查的方式很粗暴,就是通过遍历文件描述符集合的方式,当检查到有事件产生后,将此 Socket 标记为可读或可写, 接着再把整个文件描述符集合拷贝回用户态里,然后用户态还需要再通过遍历的方法找到可读或可写的 Socket,然后再对其处理。
所以,对于 select 这种方式,需要进行 2 次「遍历」文件描述符集合,一次是在内核态里,一个次是在用户态里 ,而且还会发生 2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中。
select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的,在 Linux 系统中,由内核中的 FD_SETSIZE 限制, 默认最大值为 1024,只能监听 0~1023 的文件描述符。
poll 不再用 BitsMap 来存储所关注的文件描述符,取而代之用动态数组,以链表形式来组织,突破了 select 的文件描述符个数限制,当然还会受到系统文件描述符限制。
但是 poll 和 select 并没有太大的本质区别,都是使用「线性结构」存储进程关注的 Socket 集合,因此都需要遍历文件描述符集合来找到可读或可写的 Socket,时间复杂度为 O(n),而且也需要在用户态与内核态之间拷贝文件描述符集合,这种方式随着并发数上来,性能的损耗会呈指数级增长。
epoll
先复习下 epoll 的用法。如下的代码中,先用epoll_create 创建一个 epol l对象 epfd,再通过 epoll_ctl 将需要监视的 socket 添加到epfd中,最后调用 epoll_wait 等待数据。
int s = socket(AF_INET, SOCK_STREAM, 0);
bind(s, ...);
listen(s, ...)
int epfd = epoll_create(...);
epoll_ctl(epfd, ...); //将所有需要监听的socket添加到epfd中
while(1) {
int n = epoll_wait(...);
for(接收到数据的socket){
//处理
}
}
epoll 通过两个方面,很好解决了 select/poll 的问题。
- 第一点,epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字,把需要监控的 socket 通过 epoll_ctl() 函数加入内核中的红黑树里,红黑树是个高效的数据结构,增删改一般时间复杂度是 O(logn)。而 select/poll 内核里没有类似 epoll 红黑树这种保存所有待检测的 socket 的数据结构,所以 select/poll 每次操作时都传入整个 socket 集合给内核,而 epoll 因为在内核维护了红黑树,可以保存所有待检测的 socket ,所以只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。
- 第二点, epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,当用户调用 epoll_wait() 函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。
从下图你可以看到 epoll 相关的接口作用:
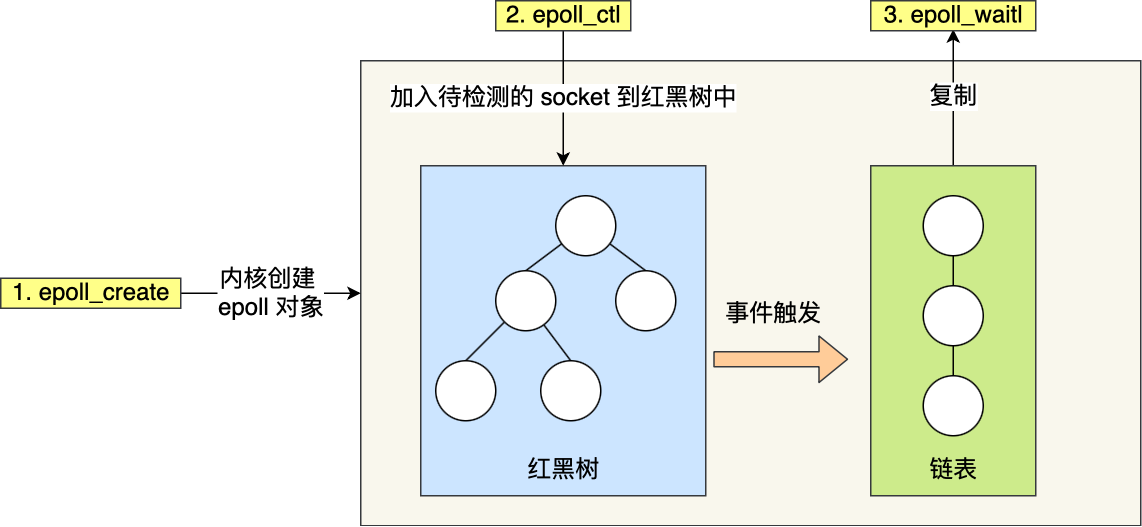
epoll 的方式即使监听的 Socket 数量越多的时候,效率不会大幅度降低,能够同时监听的 Socket 的数目也非常的多了,上限就为系统定义的进程打开的最大文件描述符个数。因而,epoll 被称为解决 C10K 问题的利器。
# https为什么可以保证数据安全?
- 加密:HTTPS 在 HTTP 的基础上添加了 SSL/TLS 协议,对传输的数据进行加密。它使用非对称加密(如 RSA)交换对称加密的密钥,然后使用对称加密(如 AES)对实际传输的数据进行加密。这样可以防止数据在传输过程中被窃取或篡改,保证了数据的机密性和完整性。
- 身份验证:通过证书机制,服务器向客户端发送数字证书,证书中包含服务器的公钥和服务器的身份信息。客户端可以验证证书的有效性,确认服务器的身份,防止中间人攻击。
# 数字证书也可以伪造,怎么办?
客户端在校验证书的时候,实际上是有一个证书链校验的过程。
根证书是整个信任链的基础,通常由操作系统或浏览器厂商内置在其系统中。这些根证书由高度可信的证书颁发机构(CA)颁发和维护。当客户端收到服务器的数字证书时,会沿着证书链向上追溯,从服务器证书到中间证书(如果有),最终到根证书。如果根证书被信任,并且整个证书链上的签名都验证通过,客户端才会信任该服务器证书。
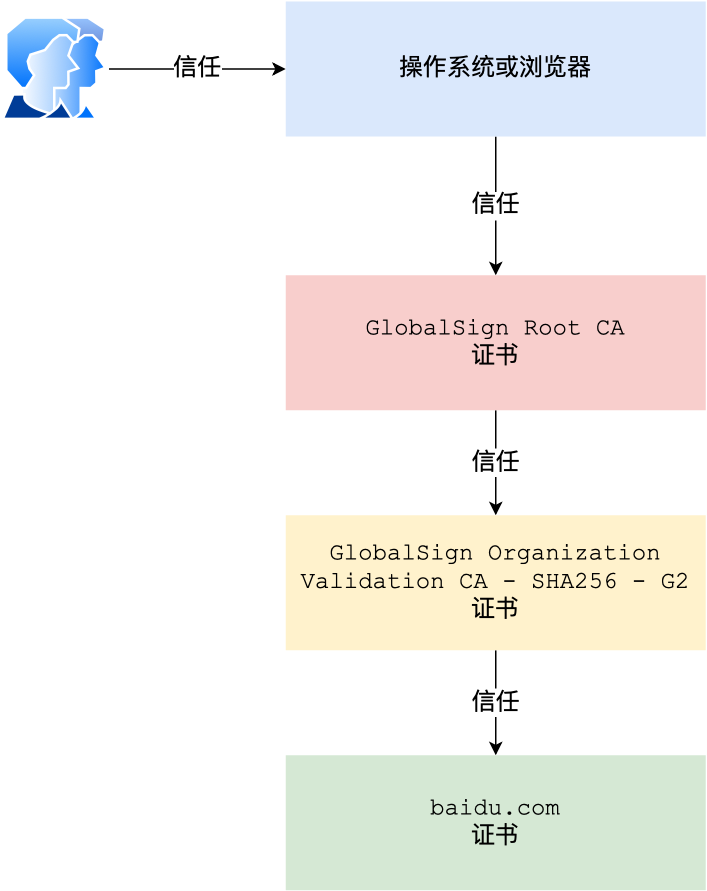
伪造一个完整的证书链,使其能够追溯到受信任的根证书非常困难,因为根证书的私钥被严密保护,只有 CA 机构自己掌握,并且 CA 机构在颁发证书时会进行严格的身份验证。
# 算法
- 在只有3种数的1000个数中快速排序?
- 一个长度为奇数的数组,快速确定中位数?
# 其他
- 你平常是如何学习技术的?
- 你最近在看什么知识点?
- 你想做什么方向?
对了,最新的互联网大厂后端面经都会在公众号首发,别忘记关注哦!!如果你想加入百人技术交流群,扫码下方二维码回复「加群」。
